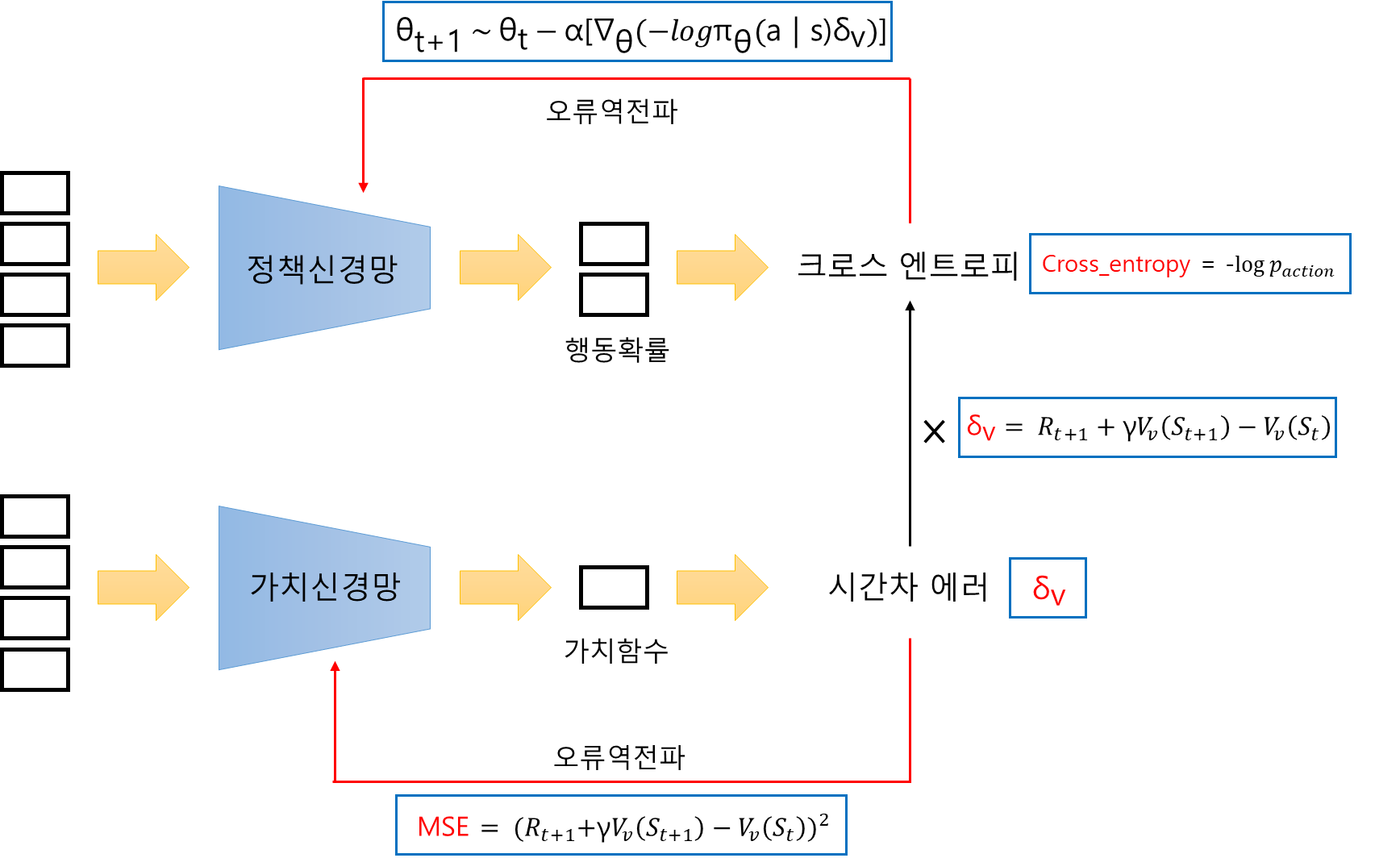
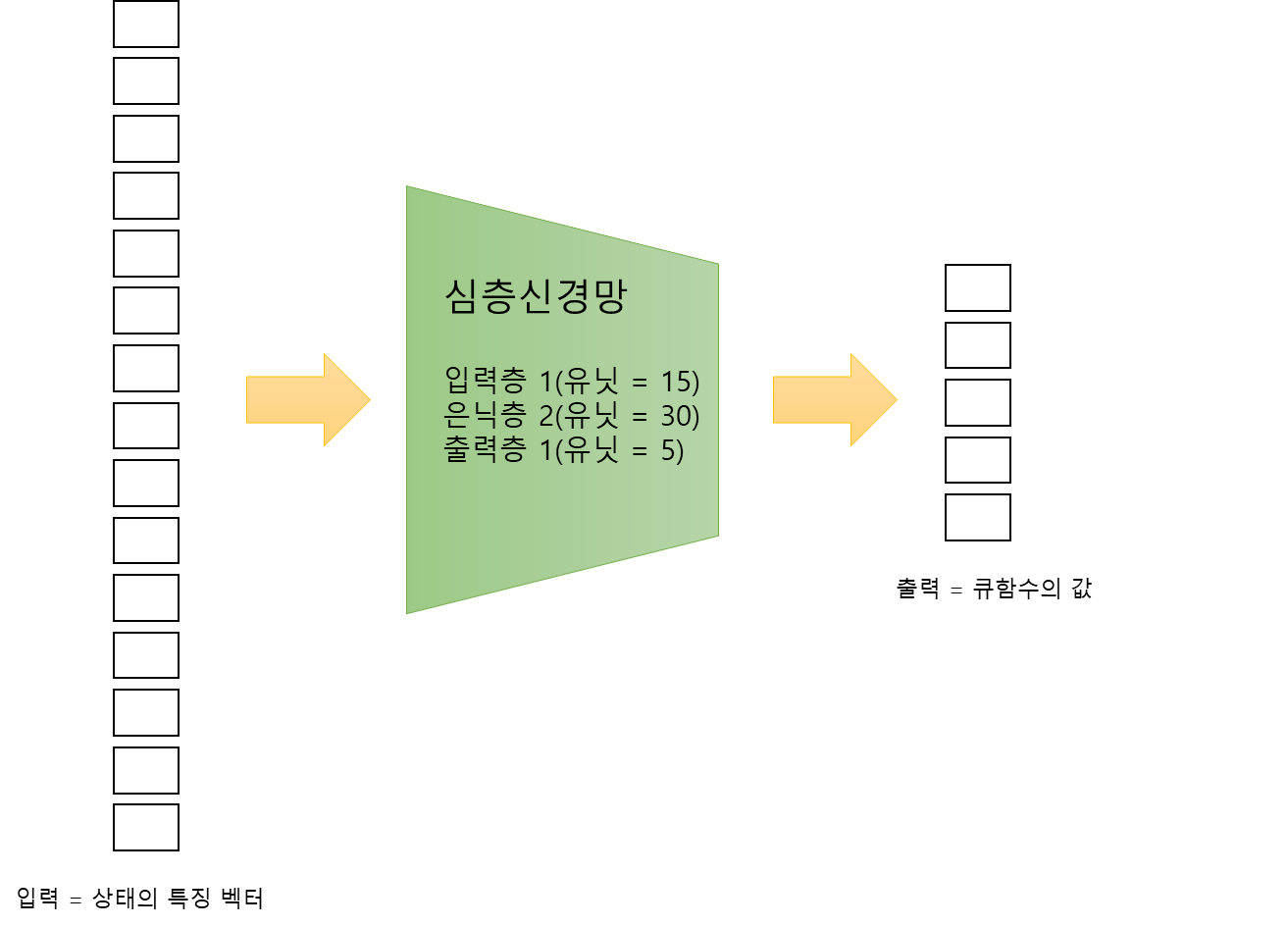
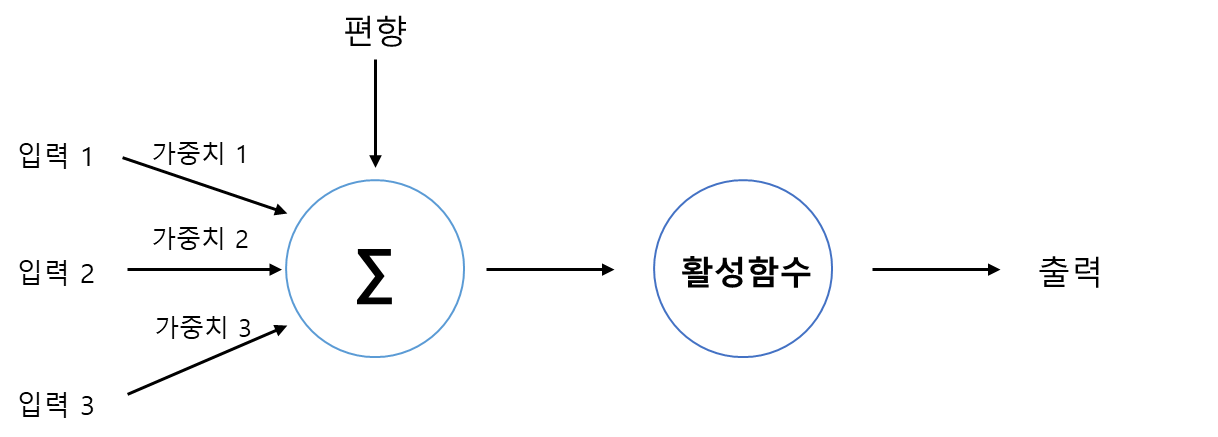
개요 지금까지 저희는 그리드월드와 카트폴과 같은 간단한 예제에 강화학습 알고리즘을 적용해봤습니다. 이 두 예제는 간단하며 인공신경망의 입력으로 사용된 상태 공간도 작았습니다. 하지만 다소 복잡하고 상태 공간이 큰 게임 화면으로부터도 에이전트는 잘 학습할 수 있을까요? 이번 포스팅부터 저희는 아타리 사의 브레이크아웃이라는 게임에서 DQN과 A3C 알고리즘을 적용해보면서 에이전트가 게임화면으로부터 어떻게 학습하는지 알아보도록 하겠습니다. 아타리: 브레이크아웃 브레이크아웃은 아타리라는 미국 게임 회사에서 만든 벽돌 깨기 게임입니다. 이 고전 게임은 2013년에 다시 유명해지게 되는데, 바로 알파고를 만든 회사로 알려진 딥마인드에서 강화학습을 통해 이 브레이크아웃 게임을 학습시켰기 때문입니다. 이때 딥마인드가 ..