개요
강화학습을 더 깊이 공부하려면 그리드월드만이 아닌 다양한 환경에서 강화학습을 적용시켜 봐야합니다.
오픈에이아이는 짐이라는 환경을 통해서 강화학습을 적용시킬 수 있는 여러 환경을 제공하는데, 저희는 이 중에서 카트폴이라는 예제에 강화학습을 적용시키며 공부할 것입니다.
저희가 이전에 배웠던 딥살사 알고리즘은 살사의 큐함수 업데이트 방법을 사용했습니다.
이번 포스팅에서는 큐러닝의 큐함수 업데이트 방법을 경험 리플레이라는 것과 함께 사용하여 인공신경망을 학습시키는 DQN 알고리즘에 대해서 알아보도록 하겠습니다.
카트폴
DQN 알고리즘을 공부하기에 앞서 저희는 카트폴 예제에 대해서 알아야합니다.
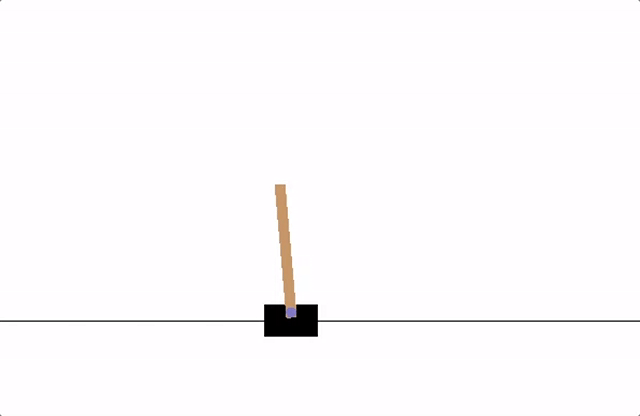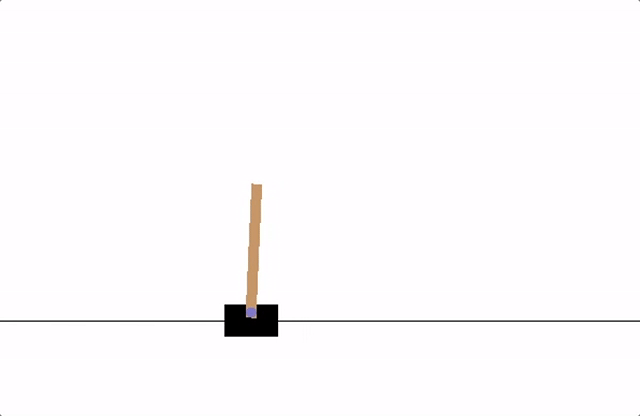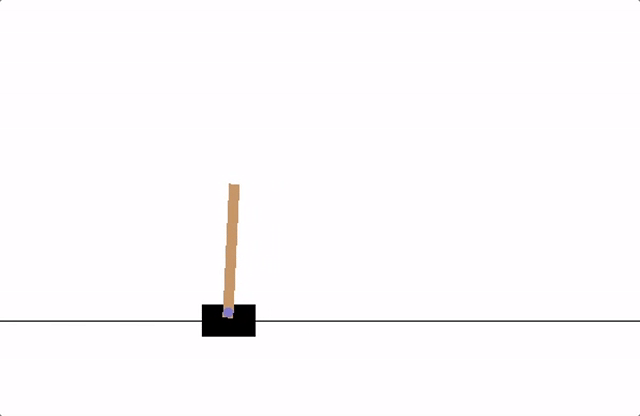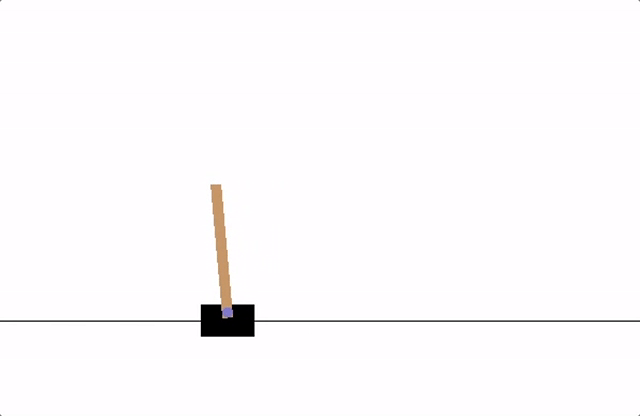
위의 그림처럼 카트폴 예제는 검은색 사각형의 카트와 황색 막대인 폴로 이루어져 있습니다. 카트는 검은색 수평선을 따라 자유롭게 움직일 수 있으며 폴은 카트와 연결된 핀을 축으로 자유롭게 회전할 수 있습니다.
에이전트는 일정한 힘으로 카트를 움직이면서 폴이 일정 각도 이상 떨어지거나 화면을 벗어나지 않도록 하는 것이 목표입니다.
목표를 이루기 위해 에이전트가 이용할 수 있는 정보는 카트의 수평선 상의 위치 $x$와 속도 $\dot{x}$ 그리고 폴의 수직선으로부터 기운 각도 $θ$와 각속도 $\dot{θ}$이며 이것들이 에이전트의 현재 상태가 되겠죠.
DQN 알고리즘
딥살사 알고리즘이 온폴리시 알고리즘인 살사와 인공신경망을 함께 사용했다면, DQN 알고리즘은 오프폴리시 알고리즘인 큐러닝과 인공신경망을 함께 사용하여 에이전트를 학습시키는 알고리즘입니다.
추가로 큐러닝과 인공신경망을 함께 사용할 때 DQN 알고리즘은 경험 리플레이라는 장치와 타깃신경망을 사용합니다.
경험 리플레이란 에이전트가 환경에서 탐험하면서 얻는 샘플(s, a, r, s')들을 메모리에 저장했다가 에이전트가 학습할 때 모인 샘플들 중 여러 개의 샘플을 무작위로 뽑아 인공신경망을 업데이트하는 방법입니다.
리플레이 메모리는 크기가 정해져있어서 메모리가 꽉차면 가장 먼저 들어온 샘플부터 메모리에서 삭제합니다.
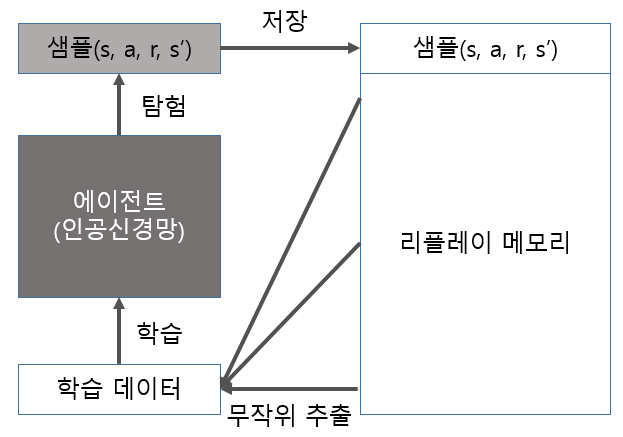
이전에 언급했듯이 살사나 딥살사와 같은 온폴리시 알고리즘은 에이전트가 안 좋은 상황에 빠져버리면 그 상황에 맞게 학습된다는 단점이 있습니다.
반면에 리플레이 메모리를 사용하면 샘플을 무작위로 뽑기 때문에 학습에 사용하는 샘플들은 서로 시간적인 상관관계가 없습니다. 따라서 온폴리시 알고리즘과 같이 에이전트가 잘못 학습되는 경우를 막을 수 있겠죠.
또한 샘플 하나가 아닌 여러 개의 샘플 데이터로 그레이디언트를 구하면 그레이디언트 값 자체의 변화가 줄어들어서 인공신경망을 좀 더 안정적으로 업데이트할 수 있습니다.
이러한 이점에 경험 리플레이 자체가 다양한 과거의 상황으로부터 학습하는 오프폴리시 알고리즘 성격을 가지고 있기 때문에 큐러닝 알고리즘과 함께 사용되는 것입니다.
이제 무작위로 뽑은 샘플들로 인공신경망을 학습시켜야합니다. DQN 알고리즘도 오류함수로 MSE를 사용하는데, 큐러닝의 큐함수 업데이트 방법을 사용한다고 했으니 MSE의 정답과 예측에 해당하는 것은 다음과 같습니다.
$Q(S_t,A_t) \leftarrow Q(S_t,A_t) + α(R_{t+1} + γ\underset{a'}{max}Q(S_{t+1},a')) - Q(S_t,A_t))$
정답 = $R_{t+1} + γ\underset{a'}{max}Q(S_{t+1},a'))$
예측 = $Q(S_t,A_t))$
이를 MSE 식에 대입하면 다음과 같습니다.
MSE = $($정답 - 예측$)^2$ = $(R_{t+1} + γ\underset{a'}{max}Q(s',a',θ)) - Q(s,a,θ))^2$
이러한 부트스트랩의 문제점은 업데이트의 목표가 되는 정답이 계속 변한다는 것입니다.
- 부트스트랩: 예측값을 이용해 또 다른 값을 예측하는 것
인공신경망 자체도 계속해서 업데이트되면 이 문제는 더 심해질 것입니다. 정답을 일정 시간동안 유지하기 위해서 사용하는 것이 바로 타깃신경망입니다.
타깃신경망이라는 것을 따로 만들어서 타깃신경망에서 정답에 해당하는 값을 구하고 이 정답을 통해 다른 인공신경망을 학습시키다가 일정한 시간 간격마다 타깃신경망을 인공신경망으로 업데이트해주는 것이죠.
그림으로 표현하면 다음과 같습니다.

타깃신경망은 $θ^-$를 매개변수로 갖는 것으로 표현하고 인공신경망을 θ를 매개변수로 갖는 것으로 표현하면 오류함수 수식은 다음과 같이 표현할 수 있습니다.
MSE = $($정답 - 예측$)^2$ = $(R_{t+1} + γ\underset{a'}{max}Q(s',a',θ^-)) - Q(s,a,θ))^2$
DQN 코드 설명
<카트폴 예제 불러오기>
import gym
if __name__ == "__main__":
# CartPole-v1 환경, 최대 타임스텝 수가 500
env = gym.make('CartPole-v1')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
# DQN 에이전트 생성
agent = DQNAgent(state_size, action_size)오픈에이아이 짐에 있는 카트폴 예제를 사용하려면 코드의 맨위에서 import gym을 선언해야 합니다.
이후 gym.make() 안에 'CartPole-v1'을 넣어 카트폴 환경을 만들어줍니다. v1이라는 의미는 500 타임스텝이 최대로 플레이이하는 시간인 카트폴 예제라는 뜻입니다. (v0은 200타임스텝이 최대인 카트폴 예제인데 현재 지원을 종료했다고 합니다.)
이제 환경 env를 선언했으니 에이전트가 필요한 상태의 크기 state_size와 행동의 크기 action_size를 가져와서 DQN 에이전트를 생성해줍니다.
에이전트는 이제 <상태에 따른 행동 선택 → 환경으로부터 보상과 다음 상태를 받음 → 샘플(s,a,r,s')을 리플레이 메모리에 저장 → 리플레이 메모리에서 무작위 추출한 샘플로 학습 → 에피소드마다 타깃신경망 업데이트> 순으로 학습을 진행할 것입니다.
<DQN 모델 정의>
# 상태가 입력, 큐함수가 출력인 인공신경망 생성
class DQN(tf.keras.Model):
def __init__(self, action_size):
super(DQN, self).__init__()
self.fc1 = Dense(24, activation='relu')
self.fc2 = Dense(24, activation='relu')
self.fc_out = Dense(action_size,
kernel_initializer=RandomUniform(-1e-3, 1e-3))
def call(self, x):
x = self.fc1(x)
x = self.fc2(x)
q = self.fc_out(x)
return q큐함수를 출력으로 하는 인공신경망을 정의하는 코드입니다. 딥살사의 인공신경망 생성 코드와 형태가 똑같지만 출력층에 kernel_initializer라는 부가적인 설정이 있는 것을 확인할 수 있습니다.
모델을 생성할 때 인공신경망의 가중치는 초깃값을 가지고 있는데, 인공신경망 학습에서 이 초깃값을 어떻게 설정하는지는 중요합니다.(특히 출력층)
큐함수가 출력이기 때문에 초기에는 각 행동에 대한 큐함수가 거의 차이 없는 것이 좋습니다.(초기에는 각 행동을 동일한 확률로 선택하는 것이 좋기 때문)
따라서 RandomUniform함수를 이용해서 출력층의 가중치가 작은 범위 내에서 초기화되도록 만들어준 것입니다.
<인공신경망과 타깃신경망 생성>
# 모델과 타깃 모델 생성
self.model = DQN(action_size)
self.target_model = DQN(action_size)
self.optimizer = Adam(lr=self.learning_rate)
# 타깃 모델 초기화
self.update_target_model()
# 타깃 모델을 모델의 가중치로 업데이트
def update_target_model(self):
self.target_model.set_weights(self.model.get_weights())이제 위의 DQN 클래스를 이용해서 인공신경망과 타깃신경망을 만들어주면 됩니다. 이 코드에서는 인공신경망과 타깃신경망을 각각 model과 target_model로 생성했습니다.
모델을 생성할 때 가중치는 무작위 과정을 통해 초기화되기 때문에 따로 생성한 model과 target_model은 같지 않습니다.
따라서 이 둘의 가중치 값을 통일시켜주어야 하는데 그 역할을 하는 것이 update_target_model 함수입니다. 이 함수는 model의 가중치 값을 가져와 target_model의 가중치 값으로 설정하는 방식입니다.
<행동 선택>
# 입실론 탐욕 정책으로 행동 선택
def get_action(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
else:
q_value = self.model(state)
return np.argmax(q_value[0])에이전트는 ε-탐욕정책으로 행동을 선택합니다. 여기서 초기 epsilon 값은 1의 값을 가지고 설정한 최솟값 epsilon_min까지 매 타임스텝마다 감소할 수 있도록 하였습니다.
따라서 에이전트는 처음에는 무작위 행동을 자주 선택하면서 탐험을 하다가 학습이 진행됨에 따라 모델의 예측에 따라 행동할 수 있습니다.
<리플레이 메모리에 샘플 저장>
# 리플레이 메모리, 최대 크기 2000
self.memory = deque(maxlen=2000)
# 샘플 <s, a, r, s'>을 리플레이 메모리에 저장
def append_sample(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))에이전트가 행동을 하고 환경으로부터 샘플(s,a,r,s')을 얻으면 이를 리플레이 메모리에 저장해야 합니다.
샘플을 append_sample 함수로 리플레이 메모리에 저장하는데, 리플레이 메모리는 deque를 사용해 일정한 크기를 가지는 메모리를 최대 2000 크기까지 사용할 수 있도록 하였습니다.
<인공신경망 업데이트>
# 리플레이 메모리에서 무작위로 추출한 배치로 모델 학습
def train_model(self):
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
# 메모리에서 배치 크기만큼 무작위로 샘플 추출
mini_batch = random.sample(self.memory, self.batch_size)
states = np.array([sample[0][0] for sample in mini_batch])
actions = np.array([sample[1] for sample in mini_batch])
rewards = np.array([sample[2] for sample in mini_batch])
next_states = np.array([sample[3][0] for sample in mini_batch])
dones = np.array([sample[4] for sample in mini_batch])
# 학습 파라메터
model_params = self.model.trainable_variables
with tf.GradientTape() as tape:
# 현재 상태에 대한 모델의 큐함수
predicts = self.model(states)
one_hot_action = tf.one_hot(actions, self.action_size) # 실제로 한 행동이 1이고 나머지는 0인 원-핫 벡터
predicts = tf.reduce_sum(one_hot_action * predicts, axis=1)
# 다음 상태에 대한 타깃 모델의 큐함수
target_predicts = self.target_model(next_states)
target_predicts = tf.stop_gradient(target_predicts) # 타깃신경망 업데이트를 막기 위한 함수
# 벨만 최적 방정식을 이용한 업데이트 타깃
max_q = np.amax(target_predicts, axis=-1)
targets = rewards + (1 - dones) * self.discount_factor * max_q
loss = tf.reduce_mean(tf.square(targets - predicts))
# 오류함수를 줄이는 방향으로 모델 업데이트
grads = tape.gradient(loss, model_params)
self.optimizer.apply_gradients(zip(grads, model_params))일단 epsilon을 타임스텝마다 감소시키기 위한 코드를 확인할 수 있습니다.
학습을 위해서는 리플레이 메모리에서 샘플을 무작위로 추출해야하기 때문에 random의 sample 함수를 이용해서 self.batch_size(여기선 64로 설정)만큼의 샘플을 추출합니다.
앞에서 샘플을 state, action, reward, next_state, done을 리스트로 묶어서 메모리에 저장했기 때문에 학습을 위해서 각각을 numpy array로 만들어주어야합니다.
이제 추출한 샘플을 아래의 식에 대입해서 오류함수을 계산합니다.
MSE = $($정답 - 예측$)^2$ = $(R_{t+1} + γ\underset{a'}{max}Q(s',a',θ^-)) - Q(s,a,θ))^2$
이때 위에서 설명했던 대로 정답($R_{t+1} + γ\underset{a'}{max}Q(s',a',θ^-)$)은 타깃신경망(target_model)으로, 예측($Q(s,a,θ)$)은 인공신경망(model)을 이용해서 계산해주면 됩니다.
타깃신경망(target_model)은 인공신경망(model)이 학습하는 도중에 학습하면 안되기 때문에 target_predicts에 tf.stop_gradient 함수를 적용하여 타깃신경망의 업데이트를 막아줍니다.
이렇게 구한 오류함수로 tape.gradient와 optimizer.apply_gradient를 통해서 인공신경망(model)을 업데이트해줍니다.
<보상과 학습 종료>
reward = 0.1 if not done or score == 500 else -1
# 이동 평균이 400 이상일 때 종료
if score_avg > 400:
agent.model.save_weights("../repos/reinforcement-learning-kr-v2-master/2-cartpole/1-dqn/save_model/model", save_format="tf")
sys.exit()이 예제에서 보상(reward)은 매 타임스텝마다 (+0.1)씩 주어지고, 500 타임스텝을 채우지 못하고 에피소드가 끝난다면 (-1)의 보상을 줍니다.
또한 에피소드 점수의 이동평균을 구하고 이동평균(score_avg)이 400점 이상이며 모델 가중치를 저장하고 학습을 종료시킵니다.
DQN 알고리즘의 전체 코드는 아래에서 확인할 수 있습니다.
https://github.com/rlcode/reinforcement-learning-kr-v2
GitHub - rlcode/reinforcement-learning-kr-v2: [파이썬과 케라스로 배우는 강화학습] 텐서플로우 2.0 개정판
[파이썬과 케라스로 배우는 강화학습] 텐서플로우 2.0 개정판 예제. Contribute to rlcode/reinforcement-learning-kr-v2 development by creating an account on GitHub.
github.com
DQN 실행 및 결과
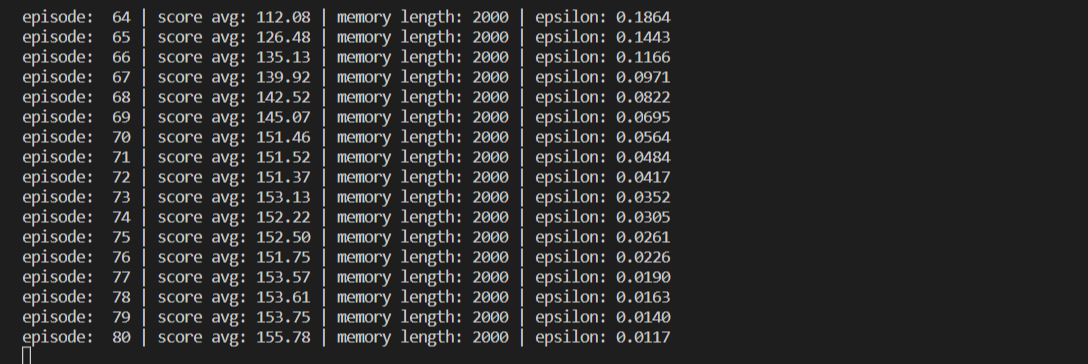
실행 결과 터미널 창에 에피소드, 평균 점수, 사용 중인 리플레이 메모리 크기, epsilon이 출력되는 것을 볼 수 있습니다.
학습이 진행됨에 따라 평균 점수는 올라가고 사용 중인 리플레이 메모리의 크기도 증가하다 최대 2000에 도달하며 epsilon 값은 에피소드마다 감소하는 것을 확인할 수 있습니다.
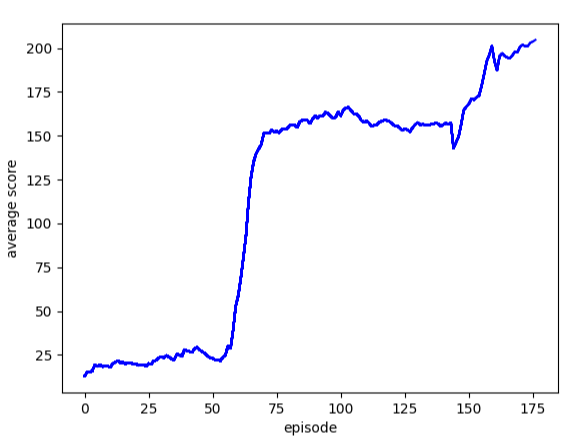
위 그림은 에피소드 별 평균 점수를 그래프로 나타낸 것으로 학습이 진행되면서 평균 점수가 높아지는 것을 볼 수 있습니다.
만약 학습이 계속 진행되다가 평균 점수가 400점 이상이 된다면 학습은 종료될 것입니다.
다음 포스팅에서는 REINFORCE 알고리즘의 발전된 형태인 액터-크리틱을 카트폴 예제에 적용시켜 코드와 함께 공부해보도록 하겠습니다. 오늘도 읽어주셔서 감사합니다~!

http://www.yes24.com/Product/Goods/44136413
파이썬과 케라스로 배우는 강화학습 - YES24
“강화학습을 쉽게 이해하고 코드로 구현하기”강화학습의 기초부터 최근 알고리즘까지 친절하게 설명한다!‘알파고’로부터 받은 신선한 충격으로 많은 사람들이 강화학습에 관심을 가지기
www.yes24.com
※ 이 글은 위의 책 내용을 바탕으로 작성한 글입니다.
'강화학습 > 파이썬과 케라스로 배우는 강화학습(스터디)' 카테고리의 다른 글
| [강화학습] 14 - 연속적 액터-크리틱 (0) | 2023.01.21 |
|---|---|
| [강화학습] 13 - 액터-크리틱 (0) | 2023.01.18 |
| [강화학습] 11 - REINFORCE 알고리즘 (1) | 2023.01.08 |
| [강화학습] 10 - 딥살사(DeepSARSA) (1) | 2023.01.03 |
| [강화학습] 09 - 인공신경망 (0) | 2022.12.30 |