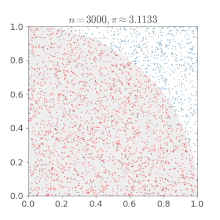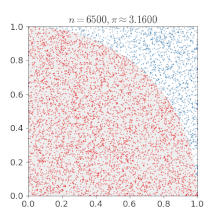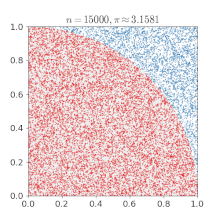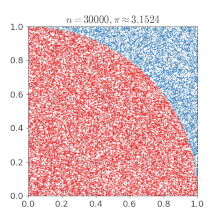
개요 이전 포스팅에서 강화학습은 환경의 모델 없이 환경과의 상호작용을 통해 최적 정책을 학습한다고 했습니다. 이때 에이전트가 환경과의 상호작용을 통해 주어진 정책에 대한 가치함수를 학습하는 것을 "예측"이라고 하고, 가치함수를 토대로 정책을 끊임없이 발전시켜 나가서 최적 정책을 학습하려는 것을 "제어"라고 합니다. 지금까지의 내용을 잘 이해했다면, 예측과 제어가 각각 앞에서 배운 정책 이터레이션의 정책 평가와 정책 발전과 비슷하다는 걸 느낄 수 있을 것입니다. 하지만 정책 이터레이션에서는 가치함수나 최적 정책을 계산을 통해 구했다면, 강화학습에서는 에이전트가 겪은 경험으로부터 가치함수를 업데이트합니다. 강화학습은 일단 해보고 → 자신을 평가하며 → 평가한 대로 자신을 업데이트하는 과정을 반복합니다. 강화..