지난 포스팅까지 two-stage detector인 R-CNN 계열의 모든 Object Detection 모델에 대해서 살펴봤다면, 이번 포스팅부터는 one-stage detector에 대해서 SSD부터 시작하여 알아보도록 하겠습니다.
즉 지금까지의 Object Detection 모델들(two-stage detector)은 Region Proposal과 Classification이 순차적으로 이루어졌다면, 이제부터 설명할 SSD를 포함한 여러 YOLO 모델들(one-stage detector)은 Region Proposal과 Classification이 동시에 이루어지는 것이죠.
SSD는 YOLOv1과 비슷한 시기에 나왔던 모델이었습니다. YOLOv1은 수행 속도는 빨랐지만 수행 성능이 Faster R-CNN보다 훨씬 떨어졌다는 문제점이 있었습니다.

반면에 위 그림과 같이 SSD는 수행 속도도 그 당시 YOLO보다 빠르고 수행 성능도 Faster R-CNN보다 좋았던, 2가지의 토끼를 모두 잡았던 Object Detection 모델이었습니다.
이런 SSD의 주요 구성 요소에는 Multi Scale Feature Layer와 Default (Anchor) Box가 있습니다. 두 구성 요소와 함께 SSD의 전반적인 과정에 대해서 살펴보도록 하겠습니다.
Multi Scale Feature Layer

이전에 배운 Sliding Window에서 detect하려는 Object가 정해진 크기의 window 안에 들어오지 않아 detect되지 않는 경우를 막기 위해서 위의 그림과 같이 원본 이미지의 scale을 계속 조절하는 식으로 해결한 것을 기억하실 것입니다.

이렇게 원본 이미지의 scale을 계속 조절하는 것을 이미지 피라미드(Image Pyramid)라고 하는데, SSD는 이와 유사한 효과를 내기 위해서 CNN을 통해 만들어진 Feature Map의 scale을 조절하여 서로 다른 크기의 Feature Map들을 기반으로 Object Detection을 수행하게 만들었습니다.

위 그림은 SSD 모델의 전체적인 구조로 여러 scale의 Feature Map을 모두 사용하여 Object Detection을 수행하는 것을 확인할 수 있습니다.
Feature Map의 size는 줄어들수록 점점 원본 이미지의 축약적이고 핵심적인 정보를 담고있기 때문에 큰 Object에 대한 detection에 용이하게 되었고, size가 커질수록 추상적인 이미지의 형태로 변하게 되면서 비교적 작은 Object에 대한 detection이 가능하게 되었습니다.
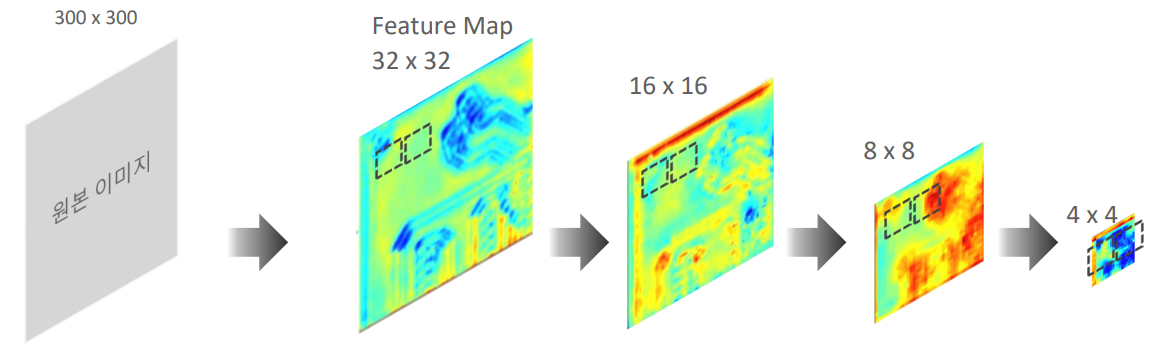
즉 초기 Feature Map에서는 비교적 작은 Object들에 대한 detection을 잘하게 되고, Feature Map의 사이즈가 커질수록 그에 맞는 큰 크기의 Object를 잘 detect하게 되는 것이죠.
여러 크기의 각 Feature Map은 Detector & Classifier를 통과시켜 detect 결과를 얻는데 이때 사용하는 것이 Default (Anchor) Box입니다.

Default (Anchor) Box
Default Box는 Faster R-CNN에서의 Anchor box와 같은 개념으로, SSD에서는 Faster R-CNN과 다르게 이 Default Box만을 가지고 Object Detection과 Region Proposal을 함께 진행한다는 특징이 있습니다.
각 Feauture Map에서 Default Box들을 생성한 후 각 Default Box에 대해서 Classification과 Bounding Box Regression을 수행시켜주고 이를 학습시킴으로써 Object Detection을 수행하는 것이죠.
이때 Default Box는 정해진 수식과 비율에 따라 일정 개수(논문에서는 4개 or 6개)만큼 생성되고, 3 x 3 convolution 계산으로 Default Box마다 Classification과 Bounding Box Regression 결과값이 계산되게 됩니다. (이때 padding을 1로 설정하여 feature map의 크기는 유지)
따라서 다음 그림과 같이 하나의 Default Box 별로 20(20개의 class별 확률) + 1(background class 확률) + 4(예측 Bounding Box 좌표로의 조절(offset) 값) = 25개의 결과값이 나오게 됩니다.
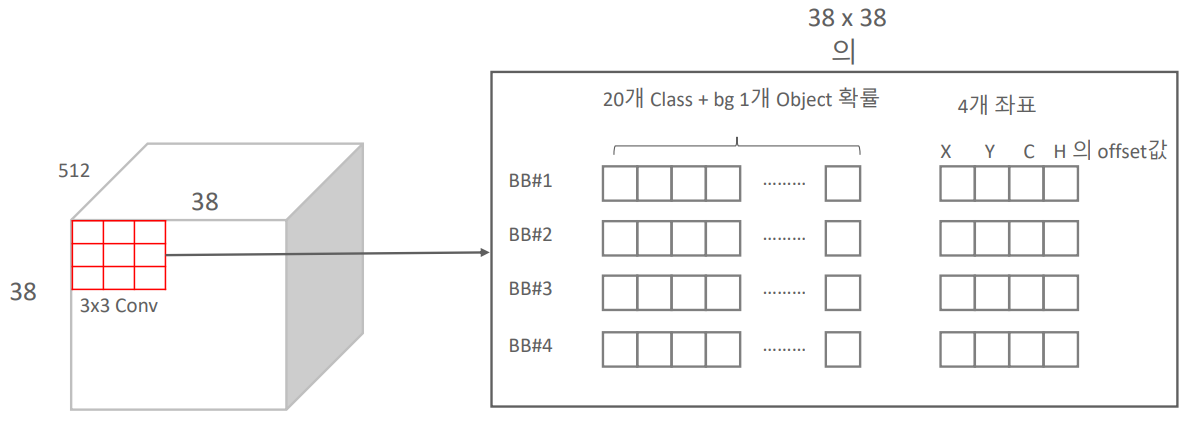
이런 Feature Map별 생성된 Default Box의 detect 결과값들은 이후 하나로 합쳐지게 되고, 최종적으로 아래 그림과 같이 Class 별로 8732개의 Default Box와 detect 결과값들이 모이게 됩니다.

8732개나 되는 Default Box가 생성되었기 때문에 한 객체에 대해서 많은 Bounding Box가 할당되었을 것입니다.
SSD는 8732개의 Default Box에 Fast NMS를 적용하여 한 객체에 대해서 가장 큰 Confidence score을 가진 Bounding Box만을 남김으로써 Object Detection을 수행합니다.

Training
8732개나 되는 Default Box의 모든 detect 결과에 대해서 학습을 수행한다면 시간도 오래 걸리고 성능도 좋지 않을 것입니다.
따라서 SSD는 Ground Truth Box와 matching된 Default Box를 골라낸 뒤 이를 중심으로 학습을 수행합니다. 이때 Matching된 Default Box는 다음 2가지 조건에 따라 선택됩니다.
1. Ground Truth Box와의 IoU가 가장 높은 Default Box
2. Ground Truth Box와의 IoU가 일정 값(논문의 경우 0.5) 이상인 Default Box
학습에 사용되는 Loss 함수는 다음과 같습니다.


전체적으로 Classification Loss($L_{conf}$)와 Bounding Box Regression Loss($L_{loc}$)를 더한 후 matching 된 Default Box의 개수만큼 나눠주어($\frac{1}{N}$) Loss 값을 계산합니다.
Loss 함수들은 Faster R-CNN과 동일하게 Classification의 경우 Cross-Entrophy Loss 함수가, Regression의 경우 Smooth L1 Loss 함수가 사용되었습니다.
$L_{loc}$의 경우 Faster R-CNN의 Regression Loss와 동일하게 초기 Default Box에서 Predicted Bounding Box 네 좌표까지의 이동량 $l_i^m$과 초기 Default Box 네 좌표에서 Ground Truth Box 네 좌표까지의 이동량 $\widehat{g}_j^m$의 차이를 0이 되도록 학습시켜 Predicted Bouding Box가 Ground Truth Box를 가능한 일치시키도록 만듭니다. 식에서의 $x_{ij}^k$는 Default Box가 Groung Truth Box와 matching되었는지를 나타내는 인자로(matching되었다면 1, 아니면 0) matching된 Default Box에 대해서만 Localization Loss를 계산해줍니다.
$L_{conf}$의 경우 matching된 Default Box에 대해서 해당 박스의 Ground Truth Box와 cross entrophy loss를 계산하고 matching되지 않은 Default Box는 배경으로 판단하여 cross entrophy loss를 계산해줍니다.
Matching된 Default Box는 Positive, 나머지는 Negative로 간주하게 되는데 일반적으로 하나의 입력 이미지에 검출할 객체보다 배경 영역이 훨씬 많기 때문에 대부분의 Default Box들은 Negative로 간주됩니다. 근데 이럴 경우, Negative 데이터가 많아져 Class Imbalance라는 문제가 발생합니다. 이를 해결하기 위해 SSD는 Hard Negative Mining이 사용합니다.
Hard Negative Mining이란 Negative를 Confidence Loss 순으로 내림 정렬하여 Confidence Loss가 작은 (background인데 background class라 판단하는 확률이 작은) Negative만 선택하여 Negative와 Positive 비율을 3:1이 되도록 맞춰줍니다.
※ Class Imbalance에 대해서는 RetinaNet에서 자세히 설명하도록 하겠습니다.
성능 비교
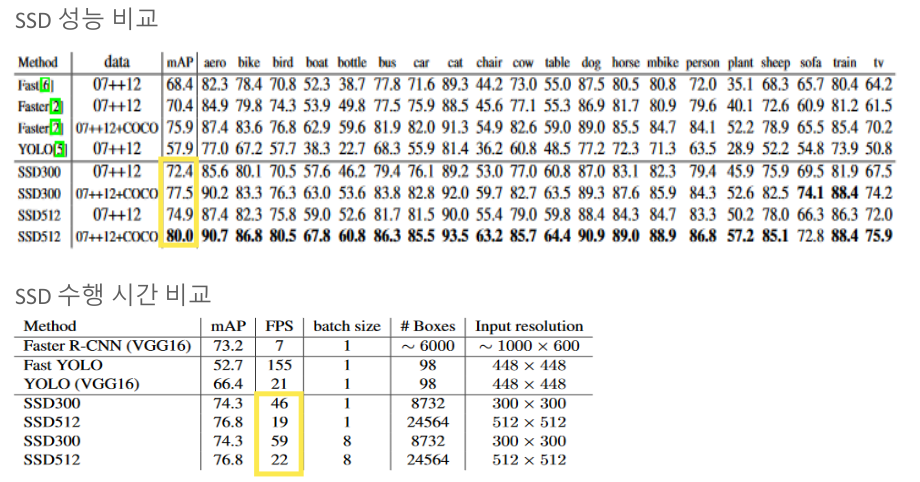
위 그림과 같이 SSD는 Faster R-CNN과 그 당시의 YOLO보다 수행 성능도 좋고, 수행 속도도 빨랐으며 특히 CPU에서의 Inference 성능이 좋았다는 장점이 있었습니다.
하지만 작은 물체는 앞쪽 layer에서 생성된 Feature map들만을 이용하여 object detection을 수행하는 만큼 작은 크기의 object에 대해서는 detect 성능이 떨어진다는 문제점이 있었습니다.
SSD는 이를 해결하기 위해 이미지를 잘라내거나 뒤집거나 sampling을 하는 등의 Data Augmentation 사용하여 어느정도 보완할 수 있었습니다.


추후 작은 Object의 detect 문제는 Feature Pyramid Network를 사용한 RetinaNet에 의해 의미 있는 개선이 됩니다.
SSD 이후 YOLO 모델은 계속해서 발전되면서 SSD보다 빠른 수행 속도와 좋은 수행 성능을 가지게 되었습니다. 다음 포스팅부터는 이 YOLO 모델에 대해서 하나씩 살펴보도록 하겠습니다.
Reference
● https://www.inflearn.com/course/딥러닝-컴퓨터비전-완벽가이드/dashboard - 인프런 강의
● https://89douner.tistory.com/94
● https://yeomko.tistory.com/13
'Perception > Object Detection' 카테고리의 다른 글
| [Object Detection] YOLOv2 (YOLO9000:Better, Faster, Stronger) (0) | 2024.03.29 |
|---|---|
| [Object Detection] YOLOv1 (You Only Look Once:Unified, Real-Time Object Detection) (0) | 2024.03.19 |
| [Object Detection] Faster R-CNN (0) | 2023.07.01 |
| [Object Detection] Fast R-CNN (0) | 2023.05.23 |
| [Object Detection] SPP(Spatial Pyramid Pooling)Net (0) | 2023.05.12 |